TD算法与MC算法最大的不同在于它是增量式的。
TD算法指一大类强化学习算法,也指一个特殊的进行状态值估计的算法
- 给定策略 π,目标是估计在策略 π 下的状态价值 {vπ(s)}s∈S。
- 经验样本为:(s0,r1,s1,…,st,rt+1,st+1,…) 或 {(st,rt+1,st+1)}t 它们是由策略 π 生成的。
v(s)⟶vπ(s)⇓v(st)⟶vπ(st)⇓vt(st)⟶vπ(st)
vt+1(st)=vt(st)−αt(st)[vt(st)−(rt+1+γvt(st+1))],(1)
vt+1(s)=vt(s),∀s=st,(2)
其中 t=0,1,2,…。
这里,vt(st) 是对 vπ(st) 的估计;αt(st) 是状态 st 在时间 t 的学习率。
- 在时间 t,仅更新访问到的状态 st 的价值,而未访问状态 s=st 的值保持不变。
- 式 (2) 的更新将在上下文清晰时省略。
相当于在没有模型的情况下求解贝尔曼公式
TD算法可以标注为:
new estimatevt+1(st)=current estimatevt(st)−αt(st)TD error δt[vt(st)−TD target vˉt(rt+1+γvt(st+1))](3)
这里:
vˉt≐rt+1+γvt(st+1)
称为 TD目标(TD target)。
δt≐vt(st)−[rt+1+γvt(st+1)]=vt(st)−vˉt
称为 TD误差(TD error)。
新估计 vt+1(st) 是当前估计 vt(st) 和 TD误差 的组合。
为什么 vˉt 被称为 TD目标?
因为算法会将 v(st) 推动向 vˉt。
vˉt≐rt+1+γvt(st+1)
为了解释这个过程:
⇒⇒⇒vt+1(st)=vt(st)−αt(st)[vt(st)−vˉt]vt+1(st)−vˉt=vt(st)−vˉt−αt(st)[vt(st)−vˉt]vt+1(st)−vˉt=[1−αt(st)][vt(st)−vˉt]∣vt+1(st)−vˉt∣=∣1−αt(st)∣⋅∣vt(st)−vˉt∣
因为 αt(st) 是一个较小的正数,有:
0<1−αt(st)<1
因此:
∣vt+1(st)−vˉt∣≤∣vt(st)−vˉt∣
这意味着 v(st) 被逐渐拉近到 vˉt!
TD误差的解释是什么?
δt=vt(st)−[rt+1+γvt(st+1)]
- 它反映了两个时间步之间的差异。
- 它反映了 vt 和 vπ 之间的差异。为说明这点,定义:
δπ,t≐vπ(st)−[rt+1+γvπ(st+1)]
注意:
E[δπ,t∣St=st]=vπ(st)−E[Rt+1+γvπ(St+1)∣St=st]=0
如果 vt=vπ,那么 δt 应该为 0(在期望意义上)。
因此,如果 δt=0,那么 vt 不等于 vπ。
TD误差可以被解释为新息(innovation),代表从经验 (st,rt+1,st+1) 中获取的新信息。
其他性质
公式(3)中的 TD算法只估计给定策略的状态价值。
- 不会估计动作价值(action value)
- 不会搜索最优策略(optimal policy)
本算法将在后续被扩展以估计动作价值并用于搜索最优策略。
公式(3)中的 TD算法是理解更复杂 TD算法的基础。
首先,这是一个无模型(model-free) 的算法,用于求解给定策略 π 的 Bellman 方程。
- 第二章中介绍了有模型(model-based) 的方法求解 Bellman 方程:解析解 + 迭代算法。
第一步,Bellman方程的新表达式
策略 π 的状态值定义为:
vπ(s)=E[R+γG∣S=s],s∈S(4)
其中 G 是折扣回报。由于:
E[G∣S=s]=a∑π(a∣s)s′∑p(s′∣s,a)vπ(s′)=E[vπ(S′)∣S=s]
其中 S′ 是下一个状态,因此我们可以将公式 (4) 改写为:
vπ(s)=E[R+γvπ(S′)∣S=s],s∈S(5)
公式 (5) 是 Bellman 方程的另一种形式,通常称为 Bellman 期望方程(Bellman expectation equation),是设计与分析 TD 算法的重要工具。
第二步,使用RM算法求解公式 (5) 中的 Bellman 方程
特别地,我们定义:
g(v(s))=v(s)−E[R+γvπ(S′)∣s]
可以将公式 (5) 改写为:
g(v(s))=0
由于我们只能获取 R 和 S′ 的样本 r 和 s′,所以我们能观测到的带噪表达为:
g~(v(s))=v(s)−[r+γvπ(s′)]=g(v(s))(v(s)−E[R+γvπ(S′)∣s])+η(E[R+γvπ(S′)∣s]−[r+γvπ(s′)])
因此,RM 算法用于求解 g(v(s))=0 的迭代过程为:
vk+1(s)=vk(s)−αkg~(vk(s))=vk(s)−αk(vk(s)−[rk+γvπ(sk′)]),k=1,2,3,…(6)
其中 vk(s) 是第 k 步对 vπ(s) 的估计;rk,sk′ 是第 k 步采样得到的 R,S′。
公式 (6) 中的 RM算法 与 TD算法 形式非常相似,但它们之间有两个主要区别:
区别 1: RM 算法需要样本 {(s,rk,sk′)},k=1,2,3,…
- 修改为:{(st,rt+1,st+1)},以便算法能够使用完整序列样本。
区别 2: RM算法使用 vπ(sk′)
- 修改为:使用当前估计 vt(st+1) 替代。
应用以上两点修改后,RM算法就完全等价于TD算法。
定理:
由 TD 算法 (1),当 t→∞ 且 ∑tαt(s)=∞ 且 ∑tαt2(s)<∞ 对所有 s∈S 成立时,vt(s) 以概率 1 收敛到 vπ(s)。
Remarks
- 此定理说明,在给定策略 π 下,状态价值可以通过 TD 算法估计出来。
- 条件 ∑tαt(s)=∞ 且 ∑tαt2(s)<∞ 必须对所有 s∈S 成立:
对于 ∑tαt(s)=∞:在时间步 t,
- 若 s=st,则 αt(s)>0
- 若 s=st,则 αt(s)=0
因此,∑tαt(s)=∞ 要求每个状态都必须被访问无限次(或足够多次)。
对于 ∑tαt2(s)<∞:实际中,学习率 α 常被设置为一个小常数。此时该条件不再满足。
但当 α 是常数时,仍可证明算法在期望意义上收敛。
| TD/Sarsa 学习 | MC 学习 |
|---|
| 在线学习(Online):TD是在线算法,在获得奖励后即可更新状态/动作价值。 | 离线学习(Offline):MC是离线算法,需等待整个回合结束后才能更新。 |
| 可处理持续任务(Continuing tasks):由于 TD 是在线的,它既能处理回合任务,也能处理持续任务。 | 仅适用于回合任务(Episodic tasks):MC 只能处理有终止状态的任务。 |
| 自举(Bootstrapping):TD的更新依赖于之前的估计值,因此需要初始猜测。 | 非自举(Non-bootstrapping):MC不需要初始值,直接通过样本估计状态/动作价值。 |
| 估计方差低(Low variance):TD 所需的随机变量更少,例如 Sarsa 只需 Rt+1,St+1,At+1。 | 估计方差高(High variance):如需估计 qπ(st,at),需多个奖励序列样本。假设每个回合长度为 L,动作空间为 A,则有 $ |
目标是估计给定策略 π 的动作价值
假设我们有一些经验样本: {(st,at,rt+1,st+1,at+1)}t
我们可以使用以下 Sarsa 算法来估计动作价值:
qt+1(st,at)=qt(st,at)−αt(st,at)[qt(st,at)−(rt+1+γqt(st+1,at+1))]qt+1(s,a)=qt(s,a),∀(s,a)=(st,at)
其中 t=0,1,2,…
qt(st,at) 是 qπ(st,at) 的估计值;
αt(st,at) 是依赖于 (st,at) 的学习率。
为什么这个算法叫做 Sarsa?
因为算法每一步使用的是 (st,at,rt+1,st+1,at+1)。
Sarsa 是 state-action-reward-state-action 的缩写。
Sarsa 与之前的 TD 学习算法有何关系?
我们可以将 TD 算法中的状态价值 v(s) 替换为动作价值 q(s,a),从而得到 Sarsa。
因此,Sarsa 是 TD 算法的动作价值版本。
Sarsa 算法在数学上是做什么的?
Sarsa 表示它是一个随机近似算法,用于求解如下方程:
qπ(s,a)=E[R+γqπ(S′,A′)∣s,a],∀s,a
这是 Bellman 方程在动作价值下的另一种表达方式。
定理:
通过 Sarsa 算法,当 t→∞ 且 ∑tαt(s,a)=∞ 且 ∑tαt2(s,a)<∞ 对所有 (s,a) 成立时,qt(s,a) 以概率 1 收敛到 qπ(s,a)。
Remarks
- 这个定理说明:在给定策略 π 的前提下,Sarsa 可以估计出动作价值。
强化学习(RL)的终极目标是找到最优策略。
为实现这一目标,我们可以将 Sarsa 与一个策略改进步骤相结合。这个组合后的算法仍然被称为 Sarsa。

Remarks
在 q(st,at) 被更新后,策略会立即更新。
这是基于广义策略迭代(generalized policy iteration)的思想。
策略采用的是 ε-贪婪(ε-greedy)而不是纯贪婪策略,
以在利用(exploitation)与探索(exploration)之间取得良好平衡。
核心思想很简单: 就是使用一个算法来求解给定策略下的 Bellman 方程。
复杂性出现于: 我们尝试寻找最优策略并高效执行时。
该算法更新规则如下:
qt+1(st,at)=qt(st,at)−αt(st,at)[qt(st,at)−(rt+1+γE[qt(st+1,A)])]qt+1(s,a)=qt(s,a),∀(s,a)=(st,at)
其中:
E[qt(st+1,A)]=a∑πt(a∣st+1)qt(st+1,a)≐vt(st+1)
表示在策略 πt 下,对 qt(st+1,a) 的期望。
TD目标改变了:从 Sarsa 中的 rt+1+γqt(st+1,at+1)
变为 Expected Sarsa 中的 rt+1+γE[qt(st+1,A)]
需要更多计算,但这样做的好处是可以减少估计的方差,
因为它减少了 Sarsa 中的随机变量数量。
使用的数据也略有不同:
从 {st,at,rt+1,st+1,at+1} 简化为 {st,at,rt+1,st+1}。
Expected Sarsa 是一个用于求解如下方程的随机近似算法:
qπ(s,a)=E[Rt+1+γEAt+1∼π(st+1)[qπ(St+1,At+1)]∣St=s,At=a],∀s,a
上述方程是 Bellman 方程在动作价值上的另一种表达方式。
进一步简化为:
qπ(s,a)=E[Rt+1+γvπ(St+1)∣St=s,At=a]
其中 vπ(St+1)=Ea∼π(St+1)[qπ(St+1,a)]
可以统一 Sarsa 与 MC learning
动作价值的定义为:
qπ(s,a)=E[Gt∣St=s,At=a]
折扣回报 Gt 可以有多种形式:
Gt(1)=Rt+1+γqπ(St+1,At+1)
Gt(2)=Rt+1+γRt+2+γ2qπ(St+2,At+2)
Gt(n)=Rt+1+γRt+2+⋯+γnqπ(St+n,At+n)
Gt(∞)=Rt+1+γRt+2+γ2Rt+3+⋯
⚠️ 注意:Gt=Gt(1)=Gt(2)=⋯=Gt(n)=Gt(∞),只是分解结构不同。
不同算法的目标
qπ(s,a)=E[Gt(1)∣s,a]=E[Rt+1+γqπ(St+1,At+1)∣s,a]
qπ(s,a)=E[Gt(∞)∣s,a]=E[Rt+1+γRt+2+γ2Rt+3+⋯∣s,a]
qπ(s,a)=E[Gt(n)∣s,a]=E[Rt+1+γRt+2+⋯+γnqπ(St+n,At+n)∣s,a]
qt+1(st,at)=qt(st,at)−αt(st,at)[qt(st,at)−(rt+1+γrt+2+⋯+γnqt(st+n,at+n))]
- 当 n=1,n-step Sarsa 等价于 Sarsa
- 当 n=∞,n-step Sarsa 等价于 Monte Carlo
n-step Sarsa 需要的数据是:
(st,at,rt+1,st+1,at+1,...,rt+n,st+n,at+n)
在 t 时刻,(rt+n,st+n,at+n) 尚未可得,因此需要等待到 t+n 时刻 才能更新:
qt+n(st,at)=qt+n−1(st,at)−αt+n−1(st,at)[qt+n−1(st,at)−(rt+1+γrt+2+⋯+γnqt+n−1(st+n,at+n))]
n-step Sarsa 介于 Sarsa 和 MC 两极之间,因此它的性能是两者的折中:
- 如果 n 很大,它接近 MC,方差大、偏差小
- 如果 n 很小,它接近 Sarsa,方差小、偏差大
- n-step Sarsa 也可用于 策略评估(policy evaluation)
- 它可以结合 策略改进步骤(policy improvement) 用于寻找最优策略
- 这是最广泛使用的强化学习算法之一。
- Sarsa 可以估计给定策略的动作价值,它必须与策略改进步骤结合,才能找到最优策略。
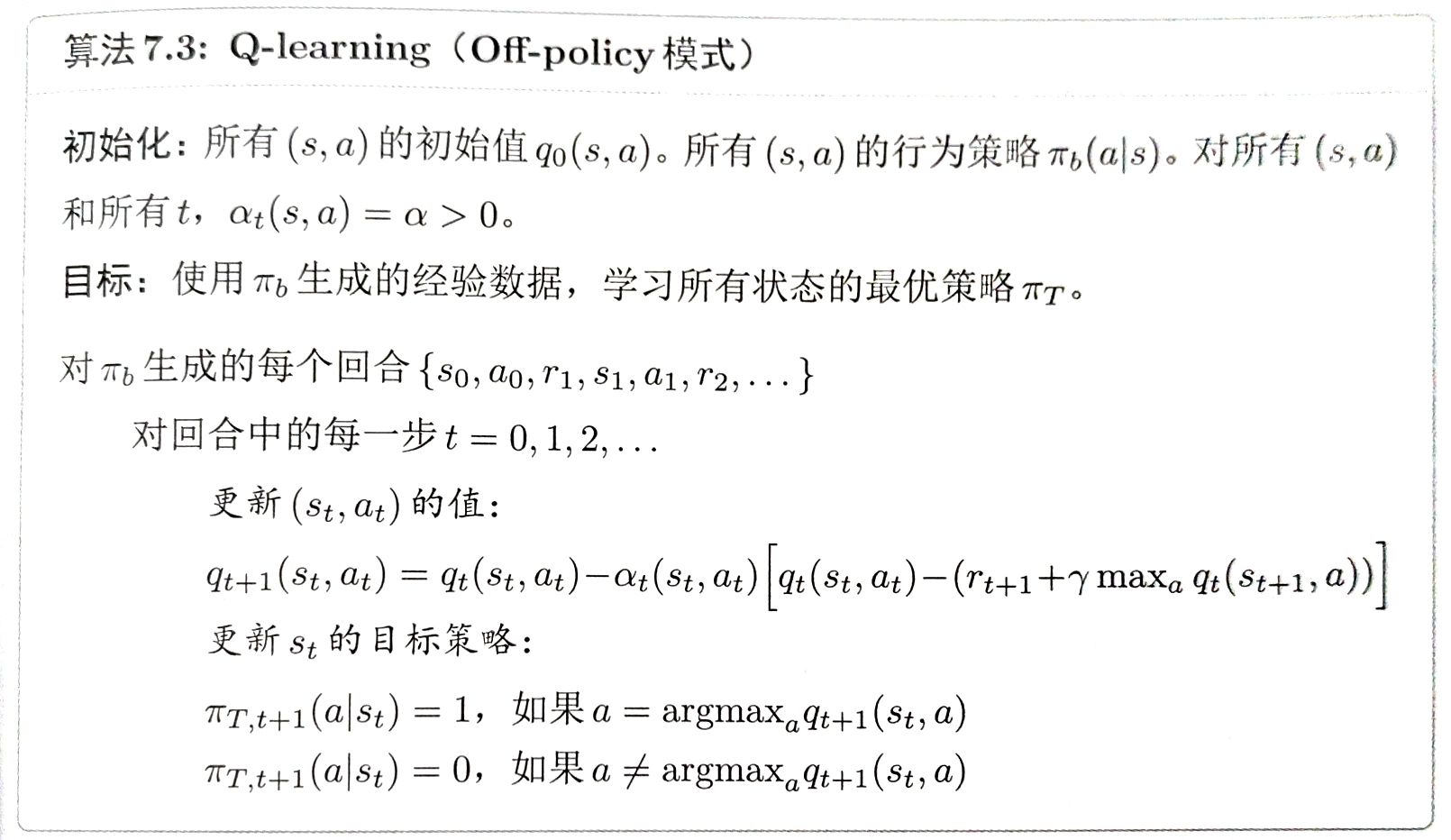
- Q-learning 可以直接估计最优动作价值,从而获得最优策略。
qt+1(st,at)=qt(st,at)−αt(st,at)[qt(st,at)−(rt+1+γa∈Amaxqt(st+1,a))],
qt+1(s,a)=qt(s,a),∀(s,a)=(st,at),
maxa∈Aqt(st+1,a):在下一个状态能获得的最大Q值
Q-learning 与 Sarsa 非常相似,它们的唯一区别在于 TD 目标:
- Q-learning 的 TD 目标是 rt+1+γmaxa∈Aqt(st+1,a)
- Sarsa 的 TD 目标是 rt+1+γqt(st+1,at+1)
它的目标是求解:
q(s,a)=E[Rt+1+γamaxq(St+1,a)∣St=s,At=a],∀s,a.
这就是用动作价值形式表达的Bellman 最优方程。
因此,Q-learning 可以直接估计最优动作价值,而不是给定策略的动作价值。
在进一步学习 Q-learning 之前,首先介绍两个重要概念:on-policy(同策略学习) 和 off-policy(异策略学习)。
在时序差分(TD)学习任务中,存在两种策略:
- 行为策略(behavior policy)用于生成经验样本;
- 目标策略(target policy)则不断朝着最优策略方向更新。
On-policy 与 off-policy 的区别:
- 当行为策略与目标策略相同时,这种学习被称为 on-policy 学习。
- 当二者不同时,则称为 off-policy 学习。
Off-policy 学习的优势:
- 它可以基于由其他任意策略生成的经验样本来寻找最优策略。
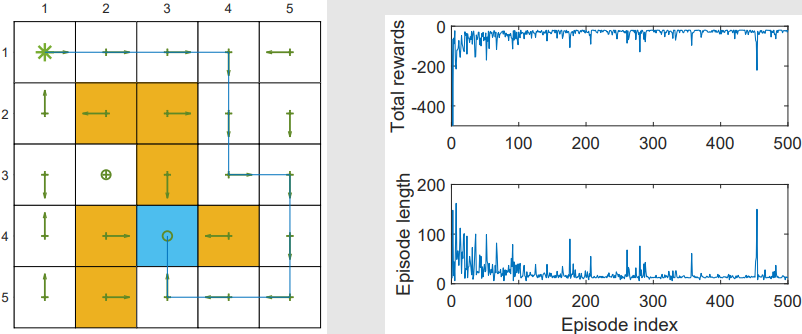
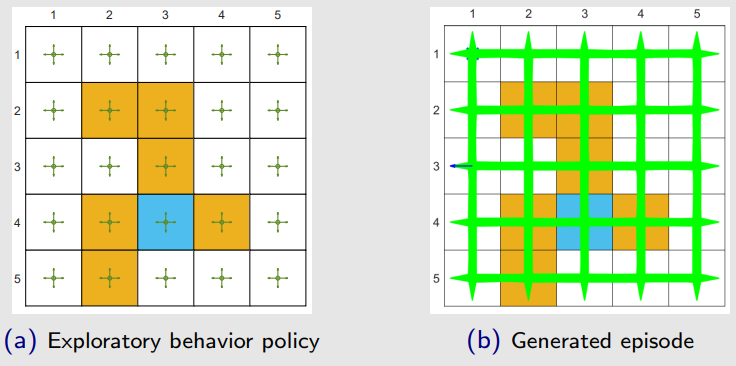
- 举例:行为策略是探索性的(exploratory),这样我们可以生成的轨迹能充分访问每一个状态-动作对。
如何判断一个 TD 算法是 on-policy 还是 off-policy?
- 首先,检查该算法旨在解决的数学问题;
- 其次,检查该算法所依赖的经验样本来源。
- Sarsa 旨在评估给定策略 π,通过求解如下方程:
qπ(s,a)=E[R+γqπ(S′,A′)∣s,a],∀s,a,
其中 R∼p(R∣s,a),S′∼p(S′∣s,a),A′∼π(A′∣S′)。
- Monte Carlo (MC) 方法也评估给定策略 π,通过求解:
qπ(s,a)=E[Rt+1+γRt+2+⋯∣St=s,At=a],∀s,a.
其中经验样本由策略 π 生成。
Sarsa 和 MC 都属于 on-policy 方法。
- 策略 π 是行为策略,因为我们需要由 π 生成的经验样本来估计它自己的动作价值。
- 同时,π 也是目标策略,因为它被持续更新,以接近最优策略。
Q-learning 是 off-policy 方法。
- 首先,Q-learning 旨在求解 Bellman 最优方程:
q(s,a)=E[Rt+1+γamaxq(St+1,a)∣St=s,At=a],∀s,a.
qt+1(st,at)=qt(st,at)−αt(st,at)[qt(st,at)−(rt+1+γa∈Amaxqt(st+1,a))]
该算法所需的样本是 (st,at,rt+1,st+1)。
- 行为策略负责在 st 中生成 at,它可以是任意策略。
由于 Q-learning 是 off-policy 的,但它也可以以 off-policy 或 on-policy 的方式实现。

- Q-learning学习到的是最优策略。
- 由于采用自举方法,算法需要选取合适的初始动作值,能加快收敛速度。
- 当行为策略的探索性较差时,学习效率明显下降。
我们在本节中介绍的所有算法都可以表示为统一的表达式:
qt+1(st,at)=qt(st,at)−αt(st,at)[qt(st,at)−qˉt]
其中,qˉt 是 TD 目标(TD target)。
不同的 TD 算法具有不同的 qˉt 表达形式:
| 算法 | qˉt 的表达式 |
|---|
| Sarsa | qˉt=rt+1+γqt(st+1,at+1) |
| n 步 Sarsa | qˉt=rt+1+γrt+2+⋯+γnqt(st+n,at+n) |
| Q-learning | qˉt=rt+1+γmaxaqt(st+1,a) |
| Monte Carlo | qˉt=rt+1+γrt+2+⋯ |
相关信息
MC 方法也可以写成这种统一形式,只需将 αt(st,at)=1。
特别地,此时的表达式为:qt+1(st,at)=qˉt。
所有 TD 算法都可以看作是用随机近似方法求解贝尔曼方程或贝尔曼最优方程:
| 算法 | 求解的方程 |
|---|
| Sarsa | BE: qπ(s,a)=E[Rt+1+γqπ(St+1,At+1)∣St=s,At=a] |
| n 步 Sarsa | BE: qπ(s,a)=E[Rt+1+γRt+2+⋯+γnqπ(st+n,at+n)∣St=s,At=a] |
| Q-learning | BOE: q(s,a)=E[Rt+1+γmaxaq(St+1,a)∣St=s,At=a] |
| Monte Carlo | BE: qπ(s,a)=E[Rt+1+γRt+2+⋯∣St=s,At=a] |
说明:
- BE 表示贝尔曼方程(Bellman Equation),用于策略评估;
- BOE 表示贝尔曼最优方程(Bellman Optimality Equation),用于最优策略学习。