▷ 如何计算均值 xˉ?
E[X]≈xˉ:=N1i=1∑Nxi.
我们有两种方法。
特别地,假设
wk+1=k1i=1∑kxi,k=1,2,…
因此,
wk=k−11i=1∑k−1xi,k=2,3,…
那么,wk+1 可以用 wk 表示为
wk+1=k1i=1∑kxi=k1(i=1∑k−1xi+xk)=k1((k−1)wk+xk)=wk−k1(wk−xk).
因此,我们得到如下迭代算法:
wk+1=wk−k1(wk−xk).
该算法的一个优点在于它是增量式(incremental)的。
一旦接收到一个样本,就可以立即得到均值的估计,并且该均值估计可以立刻用于其他目的。
由于在初始阶段样本数量不足,均值估计在一开始并不精确(即 wk=E[X])。
然而,这种估计总比没有要好。随着样本数量的不断增加,估计值可以被逐步改进,也就是说,当 k→∞ 时,
wk→E[X].
此外,考虑一种具有更一般形式的算法:
wk+1=wk−αk(wk−xk),
其中,用 αk>0 替代了 k1。
该算法是否仍然收敛到均值 E[X]?
我们将证明:如果 {αk} 满足一些较弱的条件,那么答案是肯定的。
我们还将说明,该算法是一个特殊的随机逼近(stochastic approximation, SA)算法,同时也是一个特殊的随机梯度下降(stochastic gradient descent)算法。
在下一讲中,我们将看到时序差分(temporal-difference, TD)算法具有类似但更为复杂的表达形式。
假设我们希望求解如下方程的根:
g(w)=0,
其中,w∈R 是需要求解的变量,g:R→R 是一个函数。
许多问题最终都可以被转化为这样的求根问题。
例如,假设 J(w) 是一个需要被最小化的目标函数,那么该优化问题可以等价地转化为
g(w)=∇wJ(w)=0.
需要注意的是,形如 g(w)=c(其中 c 为常数)的方程,也可以通过将 g(w)−c 视为一个新的函数,从而转化为上述形式的方程。
能够求解上述问题的 Robbins–Monro(RM)算法如下所示:
wk+1=wk−akg~(wk,ηk),k=1,2,3,…
其中:
wk 是第 k 次对方程根的估计值。
g~(wk,ηk)=g(wk)+ηk 是第 k 次的带噪观测。
- 为什么这里会有噪声?
例如,可以将其理解为:对随机变量 X 进行一次随机采样 x 所带来的随机性。
ak 是一个正的系数(步长)。
该算法依赖于数据而非模型:
输入序列(Input sequence): {wk}
输出序列(含噪声)(Output sequence, noisy):
{g~(wk,ηk)}
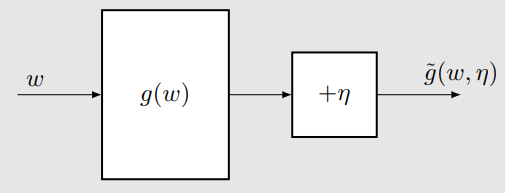
核心思想(Philosophy):没有模型,就需要数据!
设
g(w)=tanh(w−1).
方程 g(w)=0 的真实根为
w∗=1.
参数设定:
w1=3,ak=k1,ηk≡0
在这种情况下,Robbins–Monro(RM)算法为
wk+1=wk−akg(wk),
因为当 ηk=0 时,有 g~(wk,ηk)=g(wk)。
wk 收敛到真实根 w∗=1。
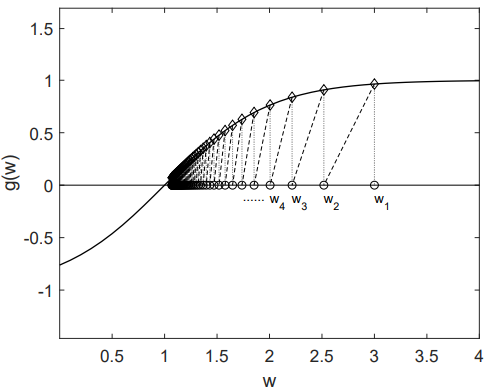
wk+1 比 wk 更接近 w∗。
当 wk>w∗ 时,有 g(wk)>0。此时 wk+1=wk−akg(wk)<wk, 因而 wk+1 比 wk 更接近 w∗。
当 wk<w∗ 时,有 g(wk)<0。此时 wk+1=wk−akg(wk)>wk, 因而 wk+1 比 wk 更接近 w∗。
上述分析是直观的,但并不严格。下面给出一个严格的收敛性结果。
在 Robbins–Monro 算法中,若满足以下条件:
对所有 w,有
0<c1≤∇wg(w)≤c2;
步长序列 {ak} 满足
k=1∑∞ak=∞,k=1∑∞ak2<∞;
噪声序列 {ηk} 满足
E[ηk∣Hk]=0,E[ηk2∣Hk]<∞;
其中 Hk={wk,wk−1,…}, 则序列 {wk} 以概率 1(w.p.1) 收敛到满足 g(w∗)=0 的根 w∗。
条件 1: 对所有 w,有
0<c1≤∇wg(w)≤c2
条件 2:
k=1∑∞ak=∞,k=1∑∞ak2<∞
- ∑k=1∞ak2<∞ 保证了当 k→∞ 时,ak→0。
- ∑k=1∞ak=∞ 保证了 ak 不会过快地收敛到 0。
条件 3:
E[ηk∣Hk]=0,E[ηk2∣Hk]<∞
首先,∑k=1∞ak2<∞ 表明当 k→∞ 时,ak→0。
其次,∑k=1∞ak=∞ 表明 ak 不能过快地收敛到 0。
为什么这个条件重要?
将
w2=w1−a1g~(w1,η1),w3=w2−a2g~(w2,η2), …,
以及
wk+1=wk−akg~(wk,ηk)
累加起来,可以得到
w1−w∞=k=1∑∞akg~(wk,ηk).
假设 w∞=w∗。如果
k=1∑∞ak<∞,
那么 ∑k=1∞akg~(wk,ηk) 可能是有界的。
此时,如果初始值 w1 被选取得距离 w∗ 很远,则上述等式将无法成立。
一种典型的选择是
ak=k1.
有如下结论成立:
n→∞lim(k=1∑nk1−lnn)=κ,
其中 κ≈0.577 被称为 Euler–Mascheroni 常数(也称为 Euler 常数)。
还值得注意的是:
k=1∑∞k21=6π2<∞.
级数 ∑k=1∞k21 在数论中有一个专门的名字,称为 巴塞尔问题(Basel problem)。
在实际中,通常选择一个小的正数。此时∑k=1∞ak=∞ 仍然成立,但∑k=1∞ak2<∞ 不再成立。选择这个的原因是它能很好地利用后面(k比较大时)得到的样本。实际上算法仍然在某种意义上收敛,可以应对时变系统。
1)考虑如下函数:
g(w)≜w−E[X].
我们的目标是求解 g(w)=0。如果能够做到这一点,那么就可以得到 E[X]。
- 均值估计(即求 E[X])可以被表述为一个求根问题(即求解 g(w)=0)。
2)我们能够获得的观测为
g~(w,x)≜w−x,
因为我们只能获得随机变量 X 的样本。注意到
g~(w,η)=w−x=w−x+E[X]−E[X]=(w−E[X])+(E[X]−x)=g(w)+η,
其中噪声项 η=E[X]−x。
3)用于求解 g(w)=0 的 RM 算法为
wk+1=wk−αkg~(wk,ηk)=wk−αk(wk−xk),
这恰好就是均值估计算法本身。因此,其收敛性也就自然得到了保证。
考虑如下随机过程:
wk+1=(1−αk)wk+βkηk,
其中 {αk}k=1∞、{βk}k=1∞、{ηk}k=1∞ 为随机序列,并且对所有 k 有 αk≥0、βk≥0。
若满足以下条件,则 wk 以概率 1(w.p.1)收敛到 0:
k=1∑∞αk=∞,k=1∑∞αk2<∞,k=1∑∞βk2<∞(以概率 1 一致成立);
E[ηk∣Hk]=0,E[ηk2∣Hk]≤C(以概率 1),
其中
Hk={wk,wk−1,…,ηk−1,…,αk−1,…,βk−1,…}.
- 该结果比 Robbins–Monro(RM)定理更一般。
- 它可以用于证明 RM 定理;
- 它可以用于分析均值估计问题;
- 其推广形式还可用于分析 Q-learning 与 TD 学习算法。
- SGD 在机器学习领域以及强化学习(RL)中被广泛使用。
- SGD 是一种特殊的 Robbins–Monro(RM)算法。
- 均值估计算法是 SGD 的一个特殊情形。
假设我们希望求解如下优化问题:
wminJ(w)=E[f(w,X)].
- w 是需要被优化的参数。
- X 是一个随机变量,期望是对 X 取的。
- w 和 X 都可以是标量或向量,而函数 f(⋅) 是一个标量函数。
wk+1=wk−αk∇wE[f(wk,X)]=wk−αkE[∇wf(wk,X)].
缺点: 计算期望需要知道随机变量 X 的分布。
E[∇wf(wk,X)]≈n1i=1∑n∇wf(wk,xi).
因此,
wk+1=wk−αkn1i=1∑n∇wf(wk,xi).
缺点: 对于每一次迭代、每一个 wk,都需要使用大量样本。
wk+1=wk−αk∇wf(wk,xk).
与梯度下降(GD)相比:
- 用随机梯度 ∇wf(wk,xk) 替代真实梯度 E[∇wf(wk,X)]。
与批量梯度下降(BGD)相比:
SGD 的思想(Idea of SGD):用随机梯度 ∇wf(wk,xk)替代了真实梯度 E[∇wf(wk,X)]。
由于
∇wf(wk,xk)=E[∇wf(w,X)],
那么,使用 SGD 时,当 k→∞,是否有 wk→w∗?
随机梯度是真实梯度的一个带噪观测:
∇wf(wk,xk)=E[∇wf(w,X)]+(∇wf(wk,xk)−E[∇wf(w,X)]),
其中括号中的部分记为噪声 η。
SGD 是一种特殊的 Robbins–Monro(RM)算法**,因此其收敛性可以自然推出。
在 SGD 算法中,若满足:
对所有 w,0<c1≤∇w2f(w,X)≤c2;
∑k=1∞ak=∞,∑k=1∞ak2<∞;
样本序列 {xk}k=1∞ 是 iid;
则wk以概率 1 收敛到 ∇wE[f(w,X)]=0的解。
证明略
假设我们希望在给定随机样本集合
{xi}i=1n
的情况下,最小化 J(w)=E[f(w,X)].
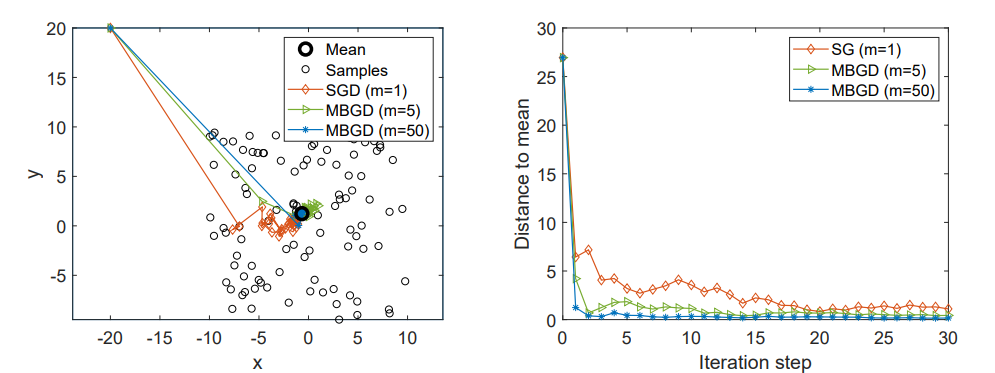
分别用于求解该问题的 BGD、SGD 与 MBGD 算法如下:
批量梯度下降(Batch Gradient Descent, BGD):
wk+1=wk−αkn1i=1∑n∇wf(wk,xi),(BGD)
小批量梯度下降(Mini-batch Gradient Descent, MBGD):
wk+1=wk−αkm1j∈Ik∑∇wf(wk,xj),(MBGD)
随机梯度下降(Stochastic Gradient Descent, SGD):
wk+1=wk−αk∇wf(wk,xk),(SGD)
在 BGD 算法中,每一次迭代都会使用全部样本。当 n 较大时,n1∑i=1n∇wf(wk,xi)会非常接近真实梯度 E[∇wf(wk,X)].
在 MBGD 算法中,Ik 是集合 {1,…,n} 的一个子集,其大小为 ∣Ik∣=m.集合 Ik 由 m 次独立同分布(iid)采样得到。
在 SGD 算法中,在第 k 次迭代时,xk是从样本集合 {xi}i=1n 中随机抽取的一个样本。