Python 基础
一、初识python
1、输入输出
print()
a = input("提示输入内容")
# map()输入
a, b, c = map(int, input().split())2、变量
变量名 = 变量值命名方式与规则
- 驼峰式
- 大驼峰
MyName首字母大写 - 小驼峰
myName除第一个单词外,首字母大写
- 大驼峰
- 链式
- 单词间下划线连接
my_name
- 单词间下划线连接
- 规则
- 所有字母大写时为常量
- 内置关键字(和函数)不作变量
本质:用来存放数据,方便数据使用与调用
3、注释
# 单行注释
"""
多行注释
"""
'''
多行注释
'''二、基本数据类型
数值类型:整型(int)、浮点型(float)、布尔型(bool)
有序序列:字符串(str)、列表(list)、元组(tuple)不可变
无序列表(散列):字典(dict)、集合(set)
type(23) # 返回数据类型
isinstance(实例对象, 直接或间接类名、基本类型或者由它们组成的元组) #判断一个对象是否是一个已知的类型isinstance() 与 type() 区别:
- type() 不会认为子类是一种父类类型,不考虑继承关系。
- isinstance() 会认为子类是一种父类类型,考虑继承关系。
如果要判断两个类型是否相同推荐使用 isinstance()。
1、布尔型
结果:True,False
数值:1,0
2、整型、浮点型
整型:第一位不可以为0(0除外)
3、序列
是一个可以存放多个值的容器
有序序列的下标
- 从左到右计数:从0往右递增
- 从右到左计数:从-1往左递减
索引与切片
变量名[起点:终点:步长]左闭右开,终点+1
包头包尾,不写下标,如[:]
步长为负,逆向输出,默认为1
字符串等数据类型都可以使用
4、字符串
创建
a='123'
b="432"
c="""
多行字符串
"""引号嵌套要使用不同引号或转义字符
| 常用转义符号 | 含义 |
|---|---|
| \' | 输出单引号 |
| \" | 输出双引号 |
| \n | 换行 |
| \t | 制表符(tab) |
| \\ | 输出 \ 或取消转义 |
| r'内容' | 原始字符串(取消所有转义) |
字符串格式化
使用占位符 %
- %s 表示字符串
- %d 表示整型
- %f 表示浮点型
- %n.mf:n表示宽度(空白补齐),m表示小数点后位数
'字符串%s' % (变量名)
print ("我叫 %s 今年 %d 岁!" % ('小明', 10))少用,同c语言
f-string
f'字符串{表达式}'
name = "小明"
print(f'我叫{name}')
# 字符串
print(f'{a:10}') # 字符串长度为10,默认右侧添加空格(若长度小于10)
print(f'{a:<10}') # 右侧填充空格
print(f'{a:>10}') # 左侧填充空格
print(f'{a:^10}') # 两侧填充空格format
'字符串{}'.format(变量) # 出现多个{}时:按先后顺序 或者 在{}中写数字对象变量下标
'fee{1}fed{0}'.format(a,b)格式化长度
同时适用于 f-string 与 format
'''规则:
^, <, > 分别是居中、左对齐、右对齐,后面加数字表示宽度
: 号后面带填充的字符,只能是一个字符,不指定则默认是用空格填充
+ 表示显示数字的正负
b、d、o、x 分别是二进制、十进制、八进制、十六进制
:n.mf 浮点数长度,n为整体宽度,m为小数点后位数
'''
# 案例
print(f'{a:10}') # 字符串长度为10,默认右侧添加空格(若长度小于10)
print('{:*<10}'.format(a)) # 字符串长度为10,右侧填充*号
print('{:b}'.format(11)) # 输出二进制
print(f'{a:+.2f}') # 带符号保留小数点后两位操作方法
添加
"431" + "3214" # + 拼接
"4" * 4 # * 重复修改与删除
s.replace('原子串', '替换串', 次数) # 替换串为空:删除;次数默认为1
s.strip() # 去首尾空格
s.lstrip() # 去除左边空格
s.rstrip() # 去除右边空格
s.upper() # 字母全大写
s.lower() # 字母全小写
s.title() # 单词首字母大写查询
s.find('字符', 起点, 终点) # 查询字符位置的最小(有多个时)下标(返回第一个字符的下标); 没有返回 -1; 起点终点可不写默认从开头到结尾
s.endswith('字符') # 判断尾部与指定字符是否相同
s.isdigit() # 判断是否全为数字
s.isalpha() # 判断是否全为字母或汉字
a.count('字符') # 统计个数
...拆分和拼接
s.split('切割字符') # 切割后切割字符删除,字符串保存为列表
s = ""
s.join(seq) # 将序列中元素以指定字符连接,返回字符串其他方法
s.center(宽度, 填充字符) # 返回指定宽度居中的字符串,填充字符默认空格5、列表
创建
#一维
列表名 = [数据, 数据, ···]
list(可迭代对象)
# 多维可以存放任意数据类型
操作方法
添加
l.append(元素) # 添加在末尾
l.extend(列表) # 将数据拆分加到末尾
l.insert(下标, 元素) # 在指定位置添加删除
l.remove(元素) # 删除指定数据,若有多个删除下标小的
l.pop(下标) # 删除指定下标的数据,若下标不存在则删除最后一个
l.clear() # 清空
del l[切片] # 删除指定区间修改
列表名[下标] = 新元素 # 若传入多个数据,以元组保存
列表名[起点:终点] = 新元素 # 新元素只能多不能少查询
l.index(数据, 起点, 终点) # 得到下标小的数据的下标,起点终点可不写默认从开头到结尾,没有则抛出ValueError
l.count(元素) # 统计某个元素在列表中出现的次数排序
# sort() 修改原列表
lst.sort(reverse=False) # reverse:降序,默认升序
# 内置函数
sorted(lst, reverse=False) # 创建新列表,默认升序
reversed(lst) # 返回一个逆序排序的迭代器对象其他方法
len(l) # 返回列表元素个数
max(l) # 返回列表元素最大值
min(l) # 返回列表元素最小值
sum(l)
l = list(seq) # 将元组或字符串转换为列表,返回列表
# 运算
a = [6] * 4 # * 重复
b = [7]
c = a + b # + 组合
# 其他
3 in [1,2,3] # 值为true
3 not in [1,2,3]列表推导式
# 列表推导式生成列表
[表达式 for 变量 in 列表]
[表达式 for 变量 in 列表 if 条件]
# 例
a = [i for i in range(10) if i%2==0]6、元组
创建
元组名 = (数据, 数据, ···)
tuple(可迭代对象)
# 定义单个元素元组
a = (34,) # 必须加逗号不可变
操作方法
访问:索引类似列表
排序:只能使用内置函数sorted()生成新列表对象
zip()
把可迭代对象中对应元素打包成一个个元组,返回由这些元组组成的列表的对象
返回列表长度与最短的对象相同
利用 zip(*) ,可以将元组解压为列表
zip([itrtable, ···]) # 返回元组迭代器
list(zip())
origin = zip(*result) # 解包元组推导式
# 与列表推导式类似
t = (x*2 for x in range(5)) # 返回生成器对象,需要转化
# 转化成列表或元组
t = tuple(t)
# 使用生成器对象的__next__()方法进行遍历
t.__next__() # 不管什么方式使用,元素只能访问一次,不能重复使用7、字典
创建
a = {}
b = dict(name='few', age=18)
k = ['name','age']
v = ['syy',18]
c = dict(zip(k,v))
d = dict.fromkeys(['name', 'age']) # 通过fromkeys创建值为None的字符串操作方法
访问
dic['name'] # [键] 获得值,若键不存在,则抛出异常
dic.get('name', default) # get() 获得值,若键不存在,返回None,可指定不存在时默认返回对象
dic.items() # 列出所有键值对
dic.keys() # 列出所有键
dic.values() # 列出所有值
len(dic)
'name' in dic # 返回键是否在字典中添加
a['新键名'] = 值 # 若键存在,则覆盖
dic1.update(dic2) # 将dic2字典的所有键值对加到dic1上,若已存在则覆盖删除
del(a['键']) # 删除指定键值对
b = a.pop('键') # 删除指定键值对,并返回值
a.clear() # 删除所有键值对
a.popitem() # 随机删除和返回键值对(字典无序)序列解包
# 字典默认对键进行操作
for i in dic # i 为键
x,y,z = [20,30,40]数据类型转换
lst = list({2:3}) # 默认转换键序列字典推导式
dic = {表达式 for 迭代变量 in 可迭代对象 [if 条件表达式]}
newdict = {v: k for k, v in olddict.items()} # 交换键值对的键与值
#enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
goods_dict = {i+1: 元素 for i, 元素 in enumerate(lis)}底层
散列表(一个稀疏数组)每个单元叫bucket,分为两部分,一个是键对象的引用,一个是值对象的引用
将键值对放进字典的底层
先计算键的哈希值,拿出最右边三位数字作为偏移量,查看对应的bucket是否为空,若空则存,否则依次取右边三位为偏移量
扩容
值接近2/3时,数组会扩容
根据键查找键值对的底层
根据键的散列值,查询偏移量
注意
- 键必须可散列
- 自定义对象要支持hash(),支持
__eq__()方法检测相等性 - 若a==b为真,则hash(a)==hash(b)也为真
- 自定义对象要支持hash(),支持
8、集合
创建和删除
a = {2,3,4}
a = set(['a','b'])
a.add(9)
a.remove(3)
a.clear()集合运算
a|b # 并集
a&b # 交集
a-b # 差集
a.union(b) # 并集
a.intersection(b) # 交集
a.difference(b) # 差集集合推导式
{ 表达式 for 迭代变量 in 可迭代对象 [if 条件表达式] }
# 与字典区分,看是否为键值对序列解包
a,b,c = ['a', 'b', 'c']三、运算符与流程控制
运算符
| 类型 | 内容 |
|---|---|
| 算术运算符 | + - * / //整除 % **幂 |
| 赋值运算符 | =、+=等 (符号左边必须为变量) |
| 比较运算符 | >、<、== 、>=、<=、!= |
| 逻辑运算符 | and、or、not(and和or会发生短路) |
| 成员运算符 | in、 not in |
运算符优先级
略 > 比较 > 成员 > 逻辑 (not > and > or)
流程控制
结构:
- 顺序结构
- 分支结构
- 循环结果
if 判断条件:
代码块
elif 判断条件:
代码块
else:
代码块
# match...case 3.10新增(笔记未完善)
match subject:
case 1:
代码块
case 2|3: # 多种情况
代码块
case _:
代码块(同default)
while 循环条件:
代码块
循环变量更新
continue
for 变量名 in 可迭代对象: # 不用手动更新变量
代码块
break # 跳出最近的循环range对象
是一个迭代器对象
range(start, end [,step=1] )
# 不包含end,没有start默认从0开始,使用zip()并行迭代
names = ("高淇","高老二","高老三","高老四")
ages = (18,16,20,25)
jobs = ("老师","程序员","公务员")
for name,age,job in zip(names,ages,jobs):
print("{0}--{1}--{2}".format(name,age,job))四、函数
1、定义
解释器遇到def时,会创建一个函数对象,并绑定到函数名变量上
def 函数名 ([参数列表]) :
'''文档字符串'''
函数体/若干语句
return 返回值 # 结束函数执行并返回值
return '6' , 6 , '6' # 返回一个元组
# 若返回多个值,可以借助列表、元组、字典、集合与序列解包
# 若无return 返回None
函数名() # 调用函数
help(函数名) # 打印文档字符串
函数名.__doc__ # __doc__属性表示文档字符串内存分析
函数为对象,存储在堆内存中(可以作为对象进行对象的操作)
函数名保存函数对象在堆内存的地址,函数名存储在栈内存
def fun1:
pass # 表示跳过,暂时不写该部分并且不会报错
fun = fun1 # 在栈内存中将函数地址赋值给新变量
fun() # 相当于调用fun12、变量作用域
全局变量
在函数和类定义之外声明的变量。作用域为定义的模块,从定义位置开始直到模块结束。
a = 100 # 全局变量
def fun():
global a # 函数内改变全局变量的值,增加global关键字声明
a = 20局部变量
在函数体中(包含形式参数)声明的变量。作用域为函数体内。
如果局部变量和全局变量同名,则在函数内隐藏全局变量,只使用同名的局部变量
局部变量的查询和访问速度比全局变量快,优先考虑使用
locals() # 返回所有局部变量
globals() # 返回所有全局变量global与nonlocal
nonlocal用来声明外层的局部变量。
global用来声明全局变量。
a=100
def outer():
b=10
def inner():
nonlocal b #声明外部函数的局部变量
print("inner b:",b)
b=20
global a #声明全局变量
a=1000
inner()
print("outer b:",b)
outer()
print("a:",a)LEGB规则
Python在查找“名称”时的步骤:Local-->Enclosed-->Global-->Builtin
- Local指的就是函数或者类的方法内部
- Enclosed指的是嵌套函数(一个函数包裹另一个函数,闭包)
- Global指的是模块中的全局变量
- Built in指的是Python为自己保留的特殊名称。
3、参数
形式参数:是在定义函数时使用的参数
实际参数:调用函数时传入的参数
函数从实参到形参的赋值操作叫做:传递参数(传参)
python都是引用传递
函数参数传递的类型
- 传递可变对象的引用
- 直接修改所传递的对象
- 传递不可变对象的引用
- 赋值操作时,,由于不可变对象无法修改,系统会创建一个对象
- 传递不可变对象包含的子对象是可变的情况
- 函数内修改了这个可变对象,源对象也发生变化
浅拷贝与深拷贝
内置函数:copy(浅拷贝)、deepcopy(深拷贝)
概念:
- 浅拷贝:不拷贝子对象的内容,只是拷贝子对象的引用。
- 深拷贝:会连子对象的内存也全部拷贝一份,对子对象的修改不会影响源对象
参数的几种类型
位置参数(必须参数)
按位置传递的参数。实参默认按位置顺序传递,需要个数和形参匹配,否则报错。
默认值参数
为某些参数设置默认值,这样这些参数在传递时就是可选的。写在位置参数后。
关键字参数(命名参数)
调用时,按照形参的名称传递参数。格式 参数名 = 参数值
可变参数
一个形参可以接收多个参数值。
- 单星号可变参数:
*args,将多个参数收集到一个 “元组” 对象中 - 双星号可变参数:
**kwargs,将多个参数收集到一个 “字典” 对象中。其中参数名保存为键(key) , 参数值保存为值(value)
def func(a,b=22, *args, **kwargs):
pass
func(2,34,55,name='syy',age='18')4、匿名函数
lambda表达式声明匿名函数。只允许包含一个表达式。
# 语法
lambda arg1,arg2,arg3... : <表达式>
# 案例
f = lambda a,b,c:a+b+c
print(f)5、高级用法
递归函数:函数自己调用自己
嵌套函数(内部函数):在函数内部定义的函数。如:闭包
6、高阶函数
eval()
函数用来执行一个字符串表达式,并返回表达式的值。字符串表达式可以包含变量、函数调用、运算符和其他 Python 语法元素。
eval(expression[, globals[, locals]])
# expression -- 表达式。
# globals -- 变量作用域,全局命名空间,如果被提供,则必须是一个字典对象。
# locals -- 变量作用域,局部命名空间,如果被提供,可以是任何映射对象。案例
x = 10
result = eval("x + 5")
print(result) # 输出: 15map()
会根据提供的函数对指定序列做映射。
map(function, iterable, ...)
# 第一个参数 function 以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的新列表。
# 返回迭代器案例
def square(x) : # 计算平方数
return x ** 2
map(square, [1,2,3,4,5]) # 计算列表各个元素的平方
list(map(square, [1,2,3,4,5])) # 使用 list() 转换为列表
# 返回[1, 4, 9, 16, 25]reduce()
对参数序列中元素进行累积。
用传给 reduce 中的函数 function(有两个参数)先对集合中的第 1、2 个元素进行操作,得到的结果再与第三个数据用 function 函数运算,最后得到一个结果。
from functools import reduce
reduce(function, iterable[, initializer])
# function -- 函数,有两个参数
# iterable -- 可迭代对象
# initializer -- 可选,初始参数案例
def add(x, y) : # 两数相加
return x + y
sum1 = reduce(add, [1,2,3,4,5]) # 计算列表和filter()
用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。
filter(function, iterable)
# 第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判断,然后返回 True 或 False,最后将返回 True 的元素放到新列表中。案例
def is_odd(n):
return n % 2 == 1
tmplist = filter(is_odd, [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]) # 判断序列是否为奇数7、闭包函数
闭:封闭关闭 。就是嵌套函数
包:对数据进行操作的函数(即内层函数对外层函数的数据进行操作),就是内层函数
闭包函数:一个函数返回它的一个内层函数(嵌套函数) , 并且这个被返回的内层函数还要使用到外层函数的变量 、参数,这个就是闭包函数
必备条件:
必须是一个嵌套函数
外层函数必须返回内层函数
内层函数必须操作外层函数中的变量或者参数基本格式:
def 函数名():
def 内层函数名():
代码
return 内层函数名本质:间接的修改数据 , 保护变量不会被破坏
# 案例
def outer():
def inner():
print(666)
return inner
outer()8、装饰器
装饰器:本质是对函数闭包的语法糖
语法糖:一种编程语法的简化或美化手段,旨在提高代码的可读性和编写效率,但并不增加语言的功能性
作用:在不修改源代码的前提下,对原有的函数增加新的功能
封闭开放原则:对修改源代码的的操作封闭(不允许修改源码) , 对增加新的功能的操作开放
添加装饰器的前提:
- 要有闭包函数的存在
- 要有被装饰的函数
同一个函数可以被多个装饰器装饰 , 一个装饰器可以被多个函数使用
# 闭包函数
def decorator_function(original_function):
def wrapper(*args, **kwargs): # 接收函数参数(通用装饰器写法)
# 这里是在调用原始函数前添加的新功能
result = original_function(*args, **kwargs) # 传入参数并记录返回值
# 这里是在调用原始函数后添加的新功能
return result # 返回未增强的返回值
return wrapper
# 使用装饰器
@decorator_function
def target_function(arg1, arg2):
pass # 原始函数的实现
target_function(arg1,arg2)
#等价于 (美化代码)
def target_function():
pass
target_function = decorator_function(target_function)
target_function()触发时机:在第一次调用之前
触发次数:只增强一次
装饰递归函数
在递归函数外套一个函数,让内部递归函数调用完后再执行装饰器相关内容
内置装饰器
类装饰器
等学完面向对象
带参装饰器
五、面向对象
1.类与对象
类的定义
class 类名:
def __init__(self): # 构造方法
self.num = 0
def fun(self):
pass
# 含构造方法的类
class Student:
def __init__(self, name, score): # 构造方法
self.name = name
self.score = score
def print_score(self):
print(self.score)实例对象
__init__()构造方法
用来初始化实例对象的实例属性
class Student:
# 定义
def __init__(self, name, score):
self.name = name # 实例属性
self.score = score
# 调用构造方法
s1 = Student('小明', 100)第一个参数固定为self。self:在刚创建的实例对象,把该对象的地址传给self
若不显式定义构造方法,系统默认创建无参构造方法
实例属性
从属于实例对象的属性,也称为“实例变量”
class c1:
# 定义
def __init__(self, 形参名):
self.实例属性名 = 形参名
# 本类其他实例方法中访问
def add():
self.实例属性名 = 1
a = c1(实参)
# 通过实例对象访问,可以给已有属性赋值,也可以新加属性
a.实例属性名 = 值实例方法
从属于实例对象的方法
class c1:
# 定义
def 方法名(self[, 形参列表]):
函数体
# 调用
对象名.方法名([实参列表])第一个参数固定为self。解释器翻译后相当于传入对象地址给实例方法
类对象
解释器执行class语句时, 就会在堆内存中创建一个类对象。
定义类时,生成了一个变量名就是类名“Student”的对象
对象含有的内容
id(identity 识别码)
type(对象类型)
value(对象的值)
- 属性(attribute)
- 方法(method)
类属性
从属于“类对象”的属性,也称为“类变量”
class C1:
sum = 0 # 定义类属性
def __init__(self):
C1.sum = C1.sum+1 # 使用类属性类方法
从属于“类对象”的方法。类方法通过装饰器@classmethod来定义
class C1:
company = "SXT"
@classmethod # 定义
def 类方法名(cls [,形参列表]):
print(cls.company)
# 调用
类名.类方法名(参数列表)第一个参数固定为cls。cls指代“类对象”本身
子类继承父类方法时,传入cls是子类对象,而非父类对象
静态方法
与“类对象”无关的方法。静态方法通过装饰器@staticmethod来定义
class C1:
company = "SXT"
@staticmethod # 定义
def 静态方法名([形参列表]) :
pass
# 调用
类名.静态方法名(参数列表)2. 三大特征
- 封装
- 继承
- 多态
2.1 封装
私有属性和私有方法
属性或方法前加两个下划线为私有的
- 类内部可以访问私有属性(方法)
- 类外部可以通过“_类名__私有属性(方法)名”访问私有属性(方法)
class Employee:
__company = "百战程序员" # 私有类属性
def __init__(self,name,age):
self.name=name
self.__age=age #私有实例属性
def __work(self): # 私有实例方法
print(6)
def say_company(self):
print("我的公司是:",Employee.__company) # 类内部可以直接访问私有属性
print(self.name,"的年龄是:",self.__age) # 类内部可以直接访问私有实例属性
self.__work() # 类内部直接调用私有方法
p1 = Employee()
print(p1._Employee__age) # 外部访问私有属性@property装饰器与setter装饰器
将一个方法的调用方式变成“属性调用”
@property主要用于帮助我们处理属性的读操作、写操作
class Employee:
def __init__(self,salary):
self.__salary = salary
@property # 相当于salary属性的getter方法
def salary(self):
print(f"月薪为{self.__salary}")
return self.__salary;
@salary.setter # 相当于salary属性的setter方法
def salary(self,salary):
self.__salary = salary # 必须是私有属性
emp1 =Employee(100)
print(emp1.salary) # 不会报错
emp1.salary =-200注意:使用setter装饰的属性必须是私有属性,否则发生栈溢出
2.2 继承
object是所有类的父类。没有指定父类,则默认父类是object类。
与Java不同:
- pyhton多继承,Java单继承
- python定义子类时只能在构造函数中显式调用父类构造函数
父类名.__init__(self, 参数列表)不会自动调用
# 使用继承
class 子类类名(父类1[,父类2,...]):
def __inti__(self,name,age,score):
self.score=score
父类名.__init__(self,name,age) # 显式调用父类构造函数- 成员继承:子类继承了父类除构造方法之外的所有成员。
- 方法重写:子类可以重新定义父类中的方法,这样就会覆盖父类的方法,也称为“重写”
- 重写的规则:
1.方法名相同
2.参数列表要数量一致
3.和返回值没有关系
- 重写的规则:
super()获得父类定义
class B(A):
def say(self):
A.say(self) # 调用父类的say方法
super().say() # 通过super()调用父类的方法
print("sayBBB")多重继承
一个子类可以有多个“直接父类”
如果父类中有相同名字的方法,在子类没有指定父类名时,解释器将 “从左向右”按顺序搜索。
MRO(MethodResolutionOrder):方法解析顺序。我们可以通过mro()方法获得 “类的层次结构”,方法解析顺序也是按照这个“类的层次结构”寻找的。
2.3 多态
同一个方法调用由于对象不同可能会产生不同的行为。
- 多态是方法的多态,属性没有多态。
- 多态的存在有2个必要条件:继承、方法重写。
案例
class People:
def __init__(self, name):
self.name = name
def drinkWater(self):
print(f'{self.name}这个人拿着杯子在喝水')
class Duck:
def __init__(self, name):
self.name = name
def drinkWater(self):
print(f'{self.name}这只鸭子正在拿嘴在河边喝水...')
def action(obj):
obj.drinkWater()
p = People('小肖')
d = Duck('小盛')
action(p)
action(d)3. 特殊方法和运算符重载
特殊方法
Python的运算符实际上是通过调用对象的特殊方法实现的
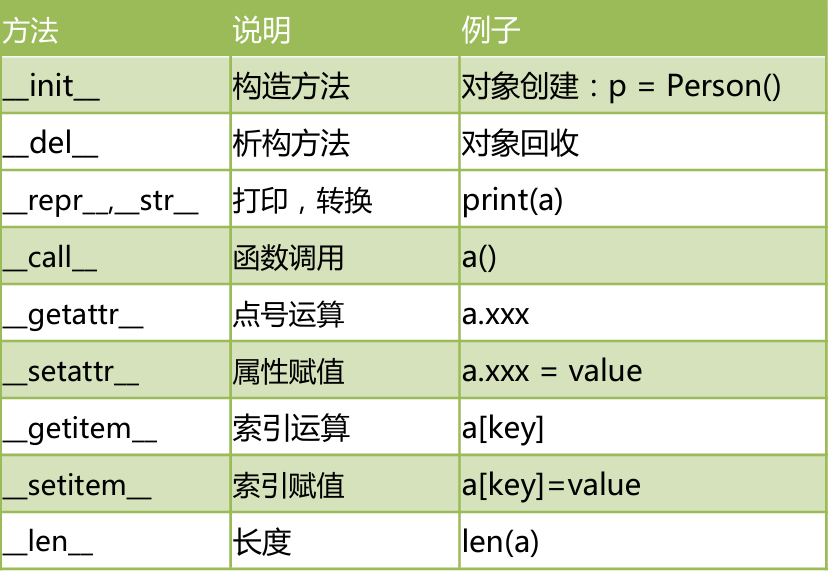
_new_()方法
用于创建对象,但我们一般无需重定义该方法
__call__方法
定义了__call__方法的对象,称为“可调用对象”,即该对象可以像函数一样被调用
class SalaryAccount:
'''工资计算类'''
def __call__(self,salary):
yearSalary=salary*12
daySalary=salary//30
hourSalary=daySalary//8
return dict(monthSalary=salary,yearSalary=yearSalary,daySalary=daySalary,hourSalary=hourSalary)
s = SalaryAccount()
print(s(5000)) #可以像调用函数一样调用对象的__call__方法__del__方法(析构函数)
实现对象被销毁时所需的操作。一般不需要自定义
当对象没有被引用时(引用计数为0),由垃圾回收器 调用__del__方法
del 类名 # 调用__del__方法运算符对应的方法
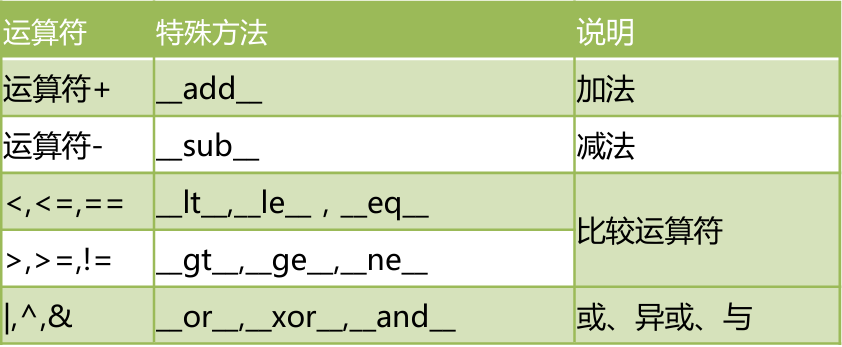
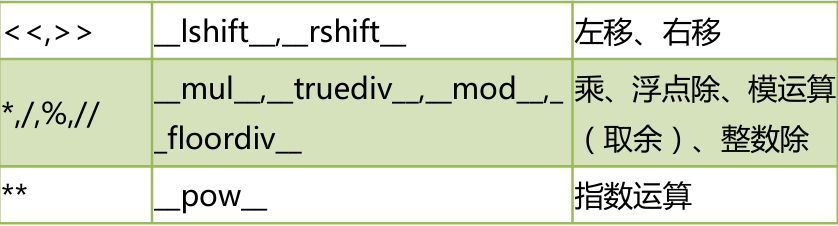
运算符重载案例
classPerson:
def __init__(self,name):
self.name=name
def __add__(self,other):
if isinstance(other,Person):
return "{0}--{1}".format(self.name,other.name)
else:
return "不是同类对象,不能相加"特殊属性
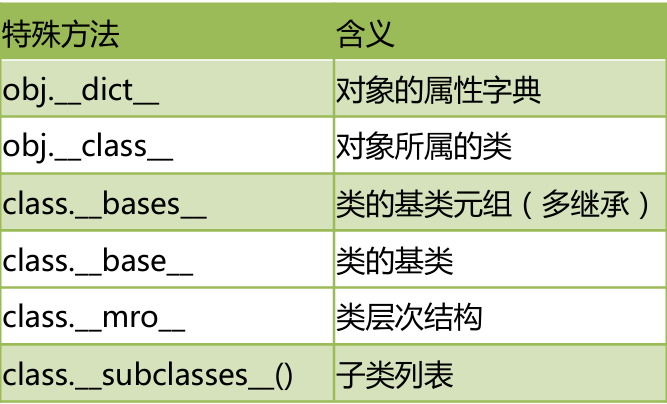
常用
dir(obj) 获取对象所有属性方法
obj.__dict__ 对象的属性字典
isinstance() 见二4. 组合
指一个类中包含其他类的实例作为其属性,这种方式可以实现代码的复用并减少类之间的依赖。
与继承相比,组合(或聚合)提供了一种更加松耦合的方式来组织代码。
案例:
class Engine:
def __init__(self, horsepower):
self.horsepower = horsepower
def start(self):
print("Engine with horsepower {} is starting.".format(self.horsepower))
class Car:
def __init__(self, model, engine):
self.model = model
self.engine = engine
def start(self):
print("Car model {} is starting its engine.".format(self.model))
self.engine.start()
# 创建一个引擎实例
engine = Engine(150)
# 创建一个汽车实例,使用上面创建的引擎
car = Car("Toyota Camry", engine)
# 启动汽车
car.start()常用查询函数
查看类的继承层次结构:
- 类名.mro()
- 类名._mro_
查看对象属性:
- dir(对象)
- obj._dict_ 对象的属性字典
isinstance(实例对象, 直接或间接类名、基本类型或者由它们组成的元组) #判断一个对象是否是一个已知的类型
issubclass(class, classinfo) # 判断参数 class 是否是类型参数 classinfo 的子类六、设计模式
设计模式是面向对象语言特有的内容,是我们在面临某一类问题时候固定的做法,设计 模式有很多种,比较流行的是:GOF(GoupOfFour)23种设计模式。
1. 工厂模式
工厂模式主要用于创建对象,特别是在涉及到对象创建的逻辑比较复杂时,或者客户端不需要知道它所创建的具体类的情况下。工厂模式可以帮助我们将对象的创建和使用解耦,增加程序的灵活性和可维护性。
class Dog:
def speak(self):
return "Woof!"
class Cat:
def speak(self):
return "Meow!"
class PetFactory:
def get_pet(self, pet_type):
if pet_type == "dog":
return Dog()
elif pet_type == "cat":
return Cat()
else:
raise ValueError("Pet type not supported")
# 使用工厂
factory = PetFactory()
pet = factory.get_pet("dog")
print(pet.speak()) # 输出: Woof!2. 单例模式
单例模式目的是确保一个类只有一个实例,并提供一个全局访问点来获取该实例。
优点:
- 控制共享资源的访问:在访问共享资源如配置文件或设备时,可以避免由于多个对象实例化而导致的资源冲突。
- 减少系统性能开销:如果对象创建开销大,可以节省系统资源,提高效率。
案例:
使用__new__方法
class Singleton:
_instance = None
def __new__(cls):
if cls._instance is None:
cls._instance = super(Singleton, cls).__new__(cls) #调用父类的__new__方法来创建类的实例并给_instance
return cls._instance
def __init__(self):
self.value = "Some data"
# 测试单例
s1 = Singleton()
s2 = Singleton()
print(s1 == s2) # 输出: True七、异常和错误
异常是Python用来管理程序执行中错误的一种方式。当Python检测到一个错误时,它会引发一个异常。如果异常没有被处理,程序就会终止并显示一个错误消息。
1. 常见内置异常
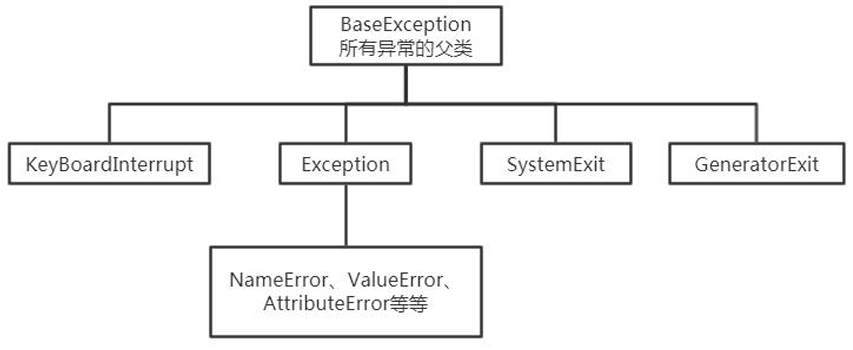
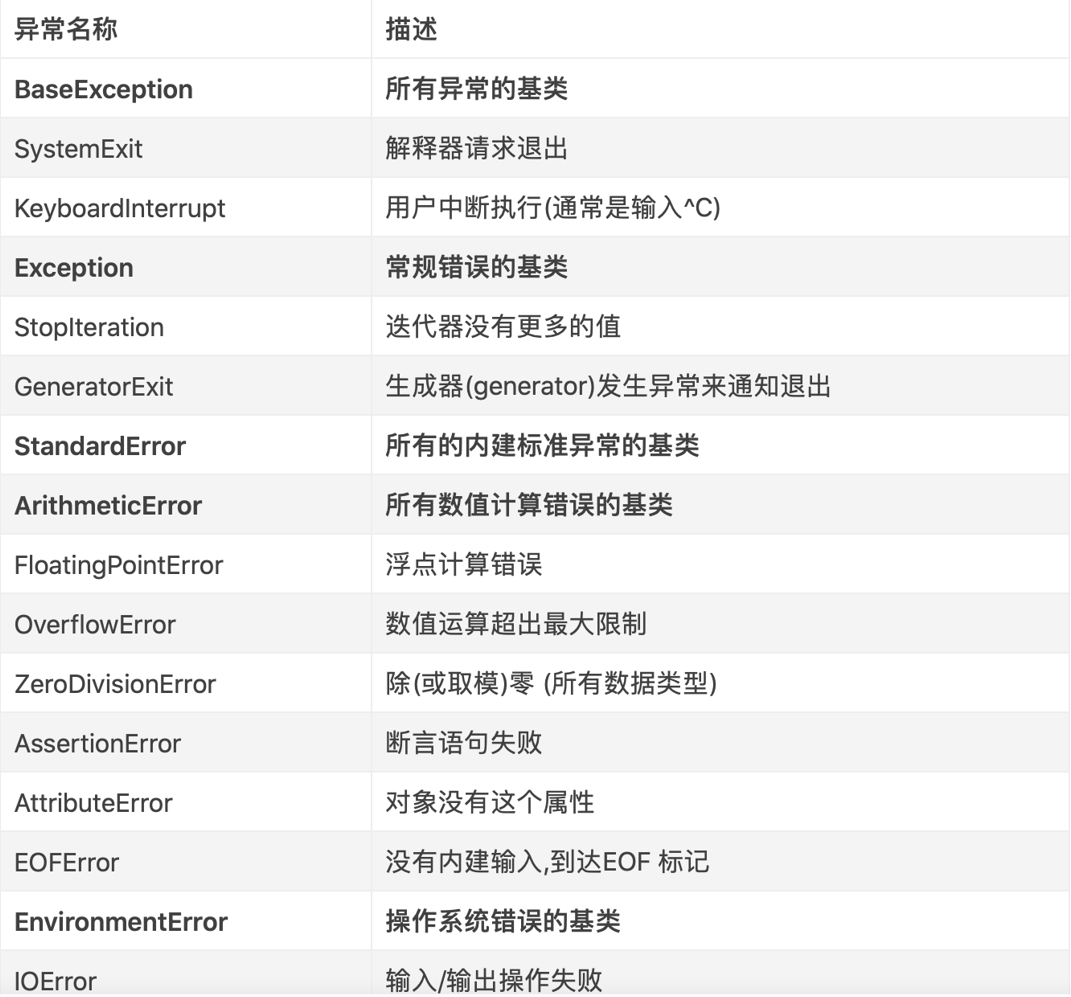
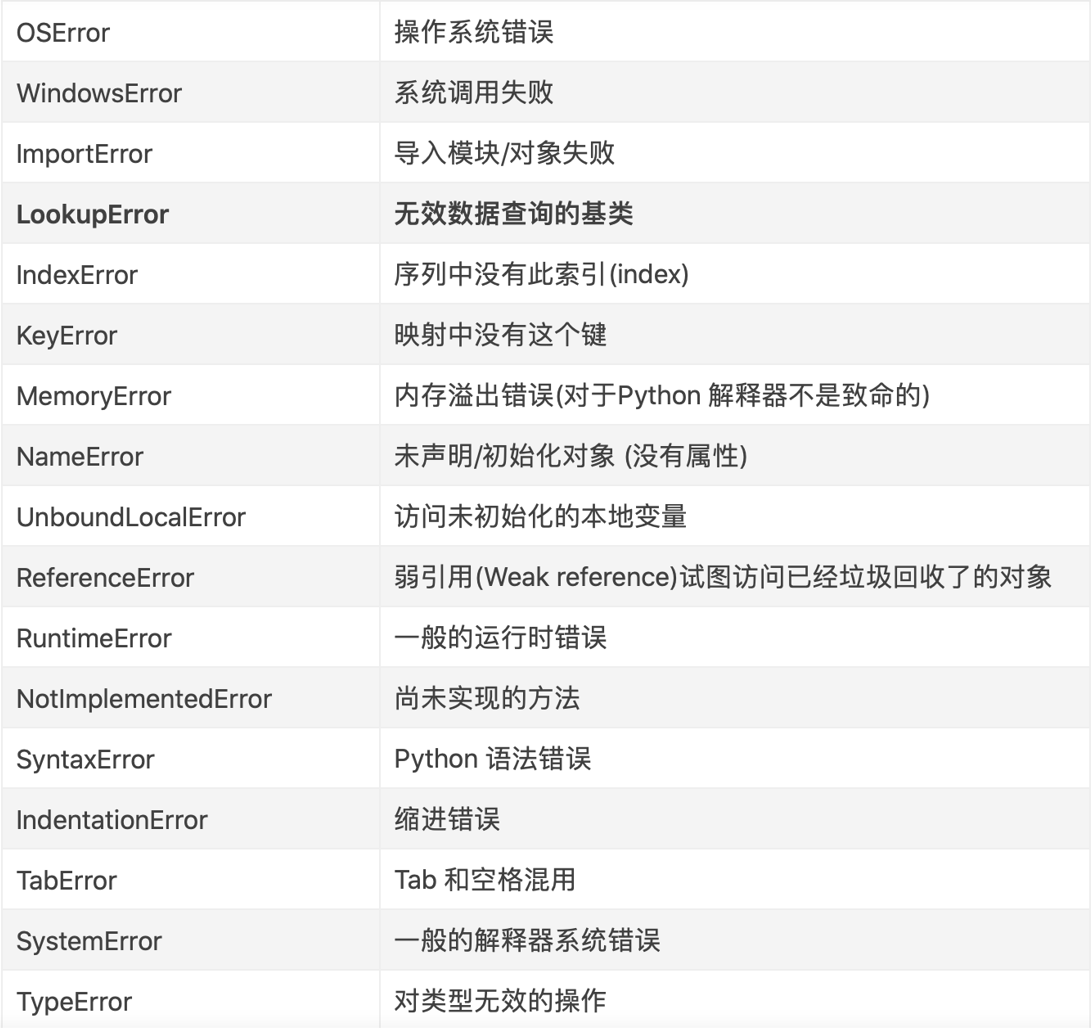
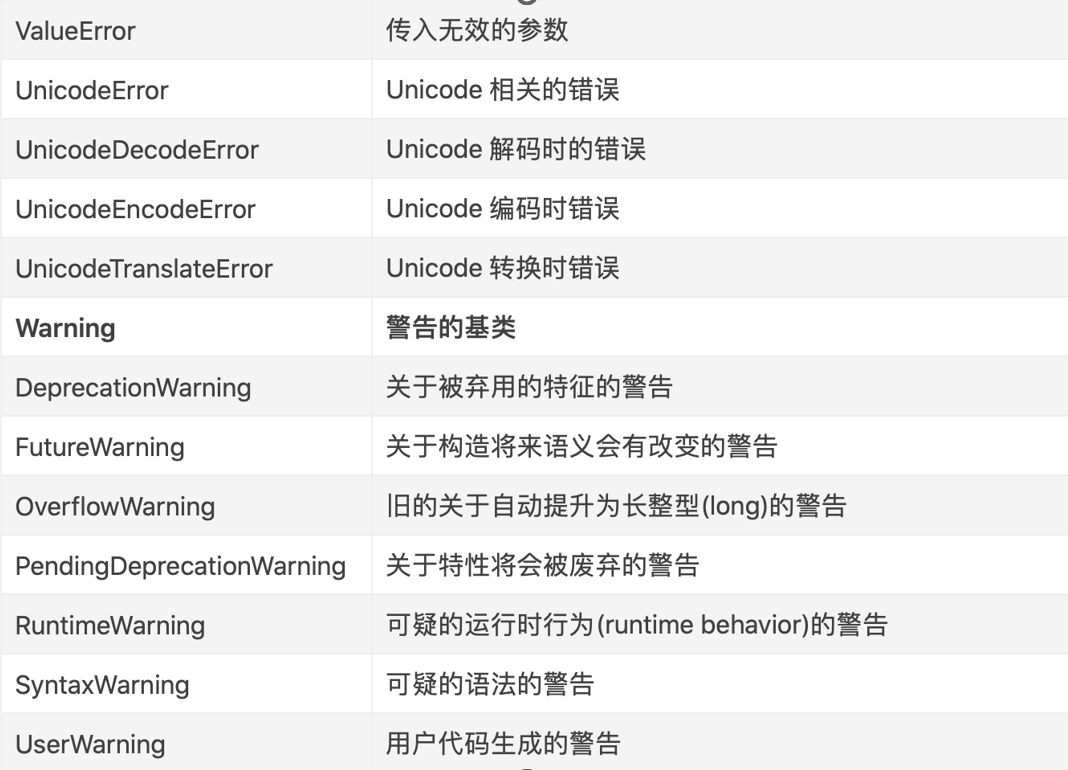
2. 自定义异常
通过继承Exception类或其子类,可以创建自定义异常。
class AgeError(Exception): #继承Exception
def __init__(self,errorInfo):
Exception.__init__(self)
self.errorInfo=errorInfo
def __str__(self):
return str(self.errorInfo)+",年龄错误!应该在1-150之间"3. 异常触发
raise语句
def check_divide(x, y):
if y == 0:
raise ValueError("The divisor cannot be zero.")
return x / y
try:
result = check_divide(10, 0)
except ValueError as e:
print(e)4. 异常处理语句
try:
# 尝试执行的代码
pass
except (TypeError, ValueError) as e:
# 处理多种异常
print(f"Error occurred: {e}")
except Exception as e:
# 处理未指定类型的所有其他异常
print("Unknown error")
else:
# 如果没有异常发生执行的代码
print("Operation successful")
finally:
# 无论是否发生异常都会执行的代码
print("Operation complete")finally通常用来释放资源
5. with上下文管理
自动管理资源。在with代码块执行完毕后自动还原进入该代码之前的 现场或上下文。不论何种原因跳出with块,不论是否有异常,总能保证资源正常释放。极 大的简化了工作,在文件操作、网络通信相关的场合非常常用。
with context_expr [ as var]:
语句块6. trackback模块
该模块提供了一个标准接口,用于提取,格式和打印Python程序的堆栈痕迹。 它完全模仿了Python解释器在打印堆栈跟踪时的行为。 当您想在程序控制下打印堆栈迹线时,这非常有用,例如在解释器周围的“包装器”中。
import traceback
try:
print("step1")
num = 1/0
except:
traceback.print_exc()八、文件操作
1. 概述
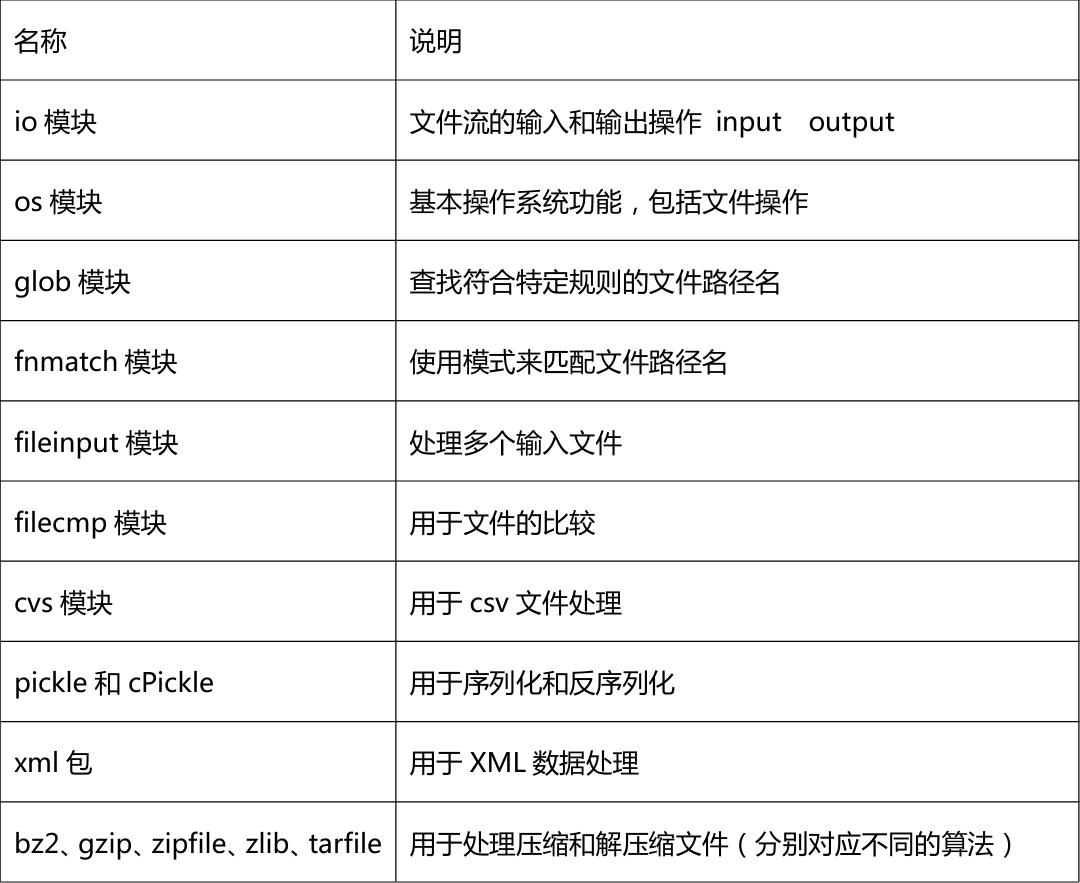
文件操作相关模块
文件编码:常用utf-8,gbk
2. 一般文件操作
创建文件对象open()
file = open('file.txt', 'r') # 'r' 表示以只读模式打开文件
# 需要关闭文件对象
file.close()
with open('file.txt', 'r', encoding='utf-8') as f: # 指定编码,只读模式
操作| 参数 | 文件模式 |
|---|---|
| 'r' | 只读模式,默认值。 |
| 'w' | 写入模式,会覆盖原有文件。如果文件不存在,则创建新文件。 |
| 'x' | 独占创建模式,如果文件已存在,引发FileExistsError。 |
| 'a' | 追加模式,写入到文件的末尾,如果文件不存在,则创建新文件。 |
| 'rb','wb' | 二进制模式。 |
| '+' | 更新模式,用于读取和写入。(与其他模式组合) |
写入文件
write(str):将字符串写入文件writelines([str1,str2]):把字符串列表写入文件,不添加换行符(一般字符串含有\n)
# 写入字符串到文件
with open('example.txt', 'w') as file:
file.write('Hello, world!\n')
# 写入多个字符串到文件
with open('example.txt', 'w') as file:
lines = ['Hello, world!\n', 'Welcome to Python file operations.\n']
file.writelines(lines)追加文件
with open('example.txt', 'a') as file:
file.write('This is an additional line.\n')读取文件
read([size]):读取size个字符,并作为结果返回。如果没有size参数,则读取整个文件。读到结尾返回空字符串。readline():读取一行内容作为结果返回。读取到文件末尾,会返回空字符串。readlines():读取文件内容到一个列表中
# 读取整个文件内容
with open('example.txt', 'r') as file:
content = file.read()
print(content)
# 逐行读取文件内容(使用迭代器)
with open('example.txt', 'r') as file:
for line in file:
print(line, end='')
# 读取文件内容到一个列表中
with open('example.txt', 'r') as file:
lines = file.readlines()
print(lines)文件定位
seek()方法来移动文件指针tell()方法来获取当前文件指针的位置
with open('example.txt', 'r') as file:
file.seek(5) # 将文件指针移动到第5个字节
content = file.read()
print(content)
position = file.tell() # 获取当前文件指针的位置
print(f'Current position: {position}')3. 二进制文件
# 使用二进制模式创建文件对象
with open('aa.gif', 'rb') as f:
with open('aa_copy.gif', 'wb') as w:
for line in f.readlines():
w.write(line)
print('图片拷贝完成!')4. pinckle序列化
序列化:将对象转化成“串行化”数据形式,存储到硬盘或通过网络传输到其他地方。
反序列化:将读取到的“串行化数据”转化成对象。
pickle.dump(obj, file):obj 就是要被序列化的对象,file指的是存储的文件pickle.load(file):从file读取数据,反序列化成对象
import pinckle
# 创建一个 Python 对象
data = {
'name': 'Alice',
'age': 30,
'is_student': False,
'courses': ['Math', 'Science', 'Art']
}
# 将对象序列化并保存到文件
with open('data.pkl', 'wb') as file:
pickle.dump(data, file)
# 从文件中反序列化对象
with open('data.pkl', 'rb') as file:
loaded_data = pickle.load(file)
print(loaded_data)5. csv文件的操作
CSV(Comma-Separated Values)文件是一种常见的文件格式,用于以纯文本形式存储表格数据。每一行数据表示一个记录,各个字段(列)之间用逗号分隔。CSV 文件通常用于数据交换,因为它们简单、易于理解和支持广泛的软件应用。
csv模块提供了读取和写入csv格式文件的对象。
reader()与writer():使用二维列表,每一行数据表示为一个列表,其中的元素是该行的字段DictReader()与DictWriter():使用外层列表内层字典,每一行数据表示为一个字典,其中的键是 CSV 文件的标题行(第一行)的字段名
reader()与writer()案例
import csv
# 读取
with open('example.csv', 'r') as file:
reader = csv.reader(file)
for row in reader:
print(row)
# 写入
data = [
['name', 'age', 'city'],
['Alice', 30, 'New York'],
['Bob', 25, 'Los Angeles'],
['Charlie', 35, 'Chicago']
]
with open('example.csv', 'w', newline='') as file:
writer = csv.writer(file)
writer.writerows(data)DictReader()与DictWriter()案例
# 读取
with open('example.csv', 'r') as file:
reader = csv.DictReader(file)
for row in reader:
print(row)
# 写入
data = [
{'name': 'Alice', 'age': 30, 'city': 'New York'},
{'name': 'Bob', 'age': 25, 'city': 'Los Angeles'},
{'name': 'Charlie', 'age': 35, 'city': 'Chicago'}
]
with open('example.csv', 'w', newline='') as file:
fieldnames = ['name', 'age', 'city']
writer = csv.DictWriter(file, fieldnames=fieldnames)
writer.writeheader() # 写入标题行
writer.writerows(data)其他:csv.Sniffer用于自动推断 CSV 文件的格式(如分隔符、引用符等)
6. os和os.path模块
直接对操作系统进行操作。我们可以直接调用操作系统的可执行 文件、命令,直接操作文件、目录等等。
os-系统操作
- os.system(str):直接调用系统的命令
- os.startfile(str):直接调用可执行文件(.exe)
import os
os.system("ping www.baidu.com")
os.startfile(r"C:\Program Files (x86)\Tencent\WeChat\WeChat.exe")os-文件操作
- remove(path):删除指定的文件
- rename(src,dest):重命名文件或目录
- stat(path):返回文件的所有属性
- listdir(path):返回path目录下的文件和目录列表
os-目录操作
- mkdir(path):创建目录
- rmdir(path):删除目录
- walk(path):递归遍历所有文件和目录
- 返回元组(指定目录的路径,目录下的所有文件夹,目录下的所有文件)
list_files = os.walk(path)
for dirpath,dirnames,filenames in list_files:
for dir in dirnames:
print(os.path.join(dirpath,dir)) # 拼接文件夹路径
for name in filenames:
print(os.path.join(dirpath,name)) # 拼接文件路径os.path 模块
- getsize(filename): 返回文件的大小(单位b)
- join(path, *path):连接多个path
- split(path):分割路径,返回列表
- splitext(path):分割出文件的扩展名,返回元组(除扩展名目录,扩展名)
- exists(path):判断指定路径的文件是否存在
- isabs(path), isdir(path), isfile(path)
7. shutil模块(拷贝和压缩)
略
九、数据库操作
9.1 SQLite数据库
在标准库内置SQLlite3模块,支持SQLite3数据库的访问和相关的数据库操作。
基本操作框架如下:
import sqlite3 # 导包
# 创建数据库文件连接对象,文件名.db
con = sqlite3.connect('d:/Project/pythonProject/test.db')
# 获取cursor对象
cur = con.cursor()
sql = '' # 要执行的sql语句
try:
cur.execute(sql) # 执行单个静态sql语句
con.commit() # 提交事务
except Exception as e:
print(e)
finally:
cur.close() # 关闭游标
con.close() # 关闭连接数据库连接对象
con = sqlite3.connect(database, timeout)
# database: 表示要访问的数据库名. 指定数据库路径,不存在则创建一个新的数据库
# timeout: 表示访问数据的超时设定数据库连接对象connect()的方法
| 方法 | 用处 |
|---|---|
| cursor() | 创建游标对象 |
| commit() | 处理事务提交,增删改数据操作需要提交 |
| rollback() | 处理事务回滚 |
| close() | 关闭数据库连接 |
创表创库等操作不用事务提交,插入数据需要提交,删除修改需要提交和报错回滚,查询则都不需要。
游标对象cursor()的方法
| 方法 | 用处 |
|---|---|
| execute() | 执行单条sql语句 |
| excutemany(sql, list) | 执行多条sql语句(效率比循环调用execute()高),借助占位符?表示变量,list内元素必须为元组 |
| fetchone() | 返回查询语句的单条记录,格式为元组。循环调用获取所有记录 |
| fetchall() | 返回查询语句的所有记录,格式为二维元组 |
案例
插入多条数据案例:
sql = 'insert into student (id,name,grade) values(?,?,?)' # 占位符 详细解释见9.2
args = []
while (True):
id = input("请输入学生的学号(按q退出创建):")
if id == "q":
break
name = input("请输入学生的姓名(按q退出创建):")
if name == "q":
break
score = input("请输入学生的成绩(按q退出创建):")
if score == "q":
break
args.append((int(id),name,int(score))) # 元素为元组
try:
cur.executemany(sql, args)
con.commit() # 需要提交
print('插入成功')
except Exception as e:
print(e)
finally:
cur.close()
con.close()查询数据案例:
# 核心代码
sql = 'select * student'
cur.execute(sql)
students = cur.fetchall()
for s in students:
print(s)修改数据案例:
try:
# 核心代码
update_sql='update student set name=? where id=?'
cur.execute(update_sql,('小明',1))
con.commit() # 提交事务
except Exception as e:
print(e)
con.rollback() # 回滚事务
finally:
# 略删除数据案例:
delete_sql='delete from student where id=?'
try:
cur.execute(delete_sql,(2,)) # 占位符
con.commit() # 提交
print('删除成功')
except Exception as e:
print(e)
print('删除失败')
con.rollback() # 回滚9.2 MySQL数据库
需要第三方库PyMySQL(本笔记介绍),或者mysql.connector
两者除创建数据库连接对象有区别外均相同
基本操作框架如下:
# PyMySQL创建数据库连接对象
import pymysql
conn = pymysql.connect(
host="localhost",
user = 'root',
password='root',
charset='utf8',
database='class7'
)
# mysql.connector创建数据库连接对象
import mysql.connector
conn = mysql.connector.connect(
host="localhost",
user="yourusername",
password="yourpassword",
database="yourdatabase"
)
# 创建游标对象
cursor = conn.cursor
# 下面操作与SQLite相同,除了占位符为`%s`占位符 %s
为了防止SQL注入攻击,我们通常使用参数化查询。参数化查询通过占位符 %s 来替换实际的参数值,从而确保SQL语句的安全性和数据的完整性
sql = 'insert into student (id,name,grade) values(%s,%s,%s)'
args = [(2, syy, 100)]
cursor.executemany(sql, args)9.3 数据库连接池
数据库连接池是一种管理数据库连接的机制,它通过维护一个连接池来提高数据库操作的效率,避免频繁的创建和销毁连接。连接池可以显著提高性能,特别是在高并发的应用场景下。
pymysql库不自带连接池,需要搭配DBUtils使用,mysql.connector含有
基本操作:(两种实现方法)
mysql.connector库
import mysql.connector
from mysql.connector import pooling
# 创建连接池
dbconfig = {
"host": "localhost",
"user": "yourusername",
"password": "yourpassword",
"database": "yourdatabase"
}
cnxpool = mysql.connector.pooling.MySQLConnectionPool(
pool_name="mypool",
pool_size=5,
**dbconfig
)
# 从连接池中获取连接
conn = cnxpool.get_connection()
# 其他操作相同,包括要conn.close()pymysql+DBUtils
import pymysql
from DBUtils.PooledDB import PooledDB
# 创建连接池
pool = PooledDB(
creator=pymysql, # 使用pymysql作为连接驱动
maxconnections=5, # 连接池允许的最大连接数
mincached=2, # 初始化时的连接数
maxcached=5, # 连接池中最多可缓存的连接数
blocking=True, # 达到最大连接数时,是否阻塞等待
host='localhost', # 数据库主机地址
user='yourusername', # 数据库用户名
password='yourpassword', # 数据库密码
database='yourdatabase', # 数据库名称
charset='utf8mb4' # 数据库编码
)
# 从连接池中获取连接
conn = pool.connection()
# 其他操作相同,包括要conn.close()附录、其他第三方库
Random库
import random
# from random import *
# 生成随机整数
print(random.randint(a, b)) #[a,b]
# 生成指定递增基数集合中的一个随机数
print(random.randrange(a,b,step))
# 生成随机浮点数
print(random.random()) #[0,1)
# 打乱顺序
random.shuffle([20,30,10,40])