2022/1/1约 1237 字大约 4 分钟
Pandas
Pandas 是 Python 的第三方库,为 Python 提供了高性能且易用的数据结构与数据分析工具。其核心数据结构 DataFrame 与 Series,能够高效处理各类结构化数据,广泛应用于数据清洗、分析、可视化等数据科学领域。
import pandas as pd
pd.options.display.max_columns = None # 设置打印所有列数据读取
| 数据类型 | 方法 |
|---|---|
| csv、tsv、txt | pd.read_csv,pd.to_csv |
| excel | pd.read_excel |
| mysql | pd.read_sql |
fpath = "xxx.csv"
data = pd.read_csv(
fpath,
sep=",",
header=None,
names=['123','34'] # 指定列名
)
df.to_csv('supplier_data.csv',mode='a',index=False,header=False) # 写入sql_data = pd.read_sql("select * from table", con=conn) # 数据库连接对象数据属性
df.head() # 查看前几行数据
df.shape # 查看数据的形状,返回(行数,列数)
df.columns # 查看列名列表
df.index # 查看索引列
df.values # 获取数据,类型是numpy.ndarray
df.dtypes # 查看数据类型数据结构
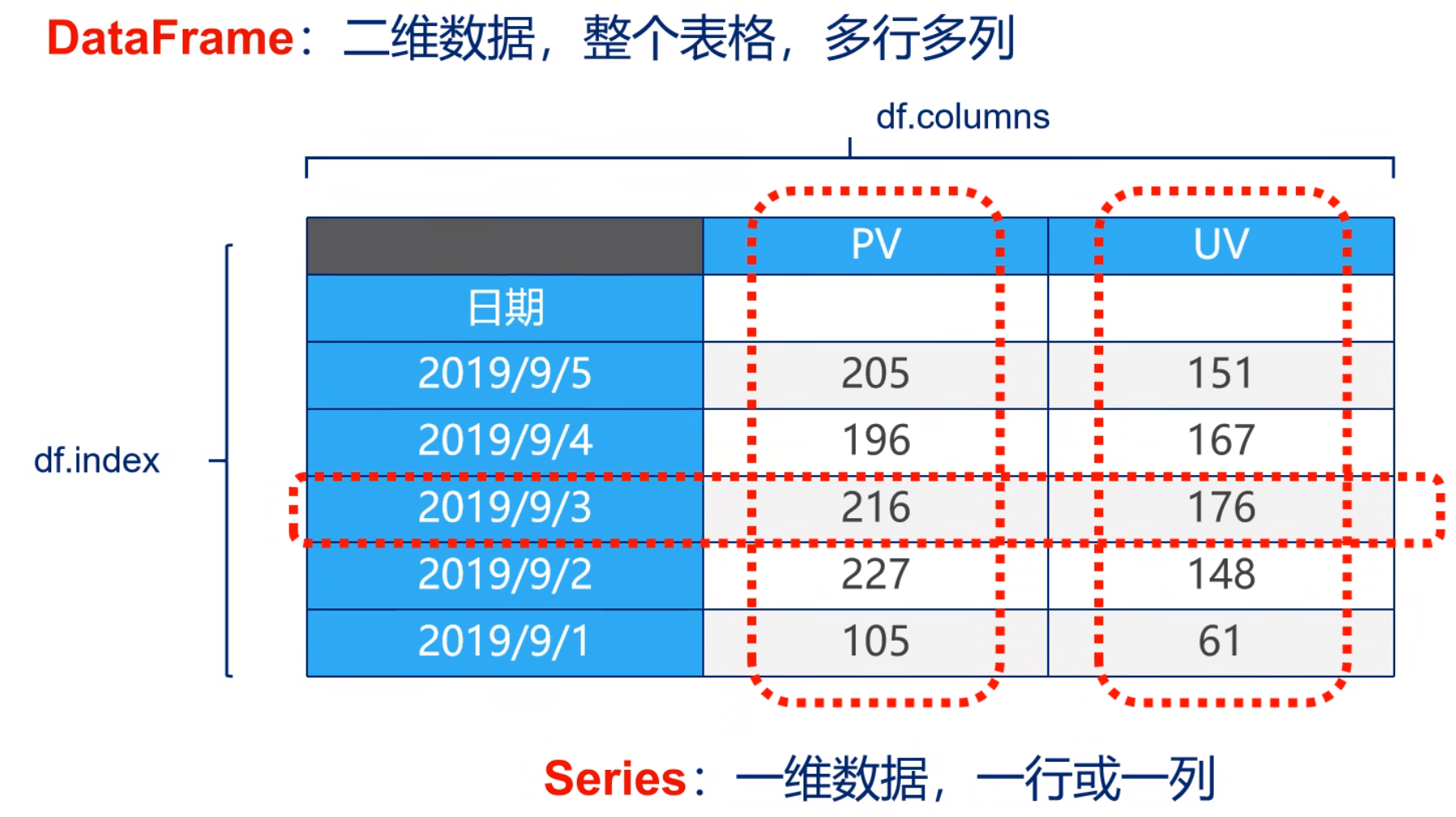
Series
类似于一维数组,由一组数据(可以是不同数据类型)以及一组与之相关的数据标签(即索引)组成。
生成
# 用列表生成索引为数字序列的Series
s1 = pd.Series([1,'a',5.2])
s2 = pd.Series([1,'a',5.2], index=['d','b','a'])
# 使用字典
sdata = {'fsge':324}
s3 = pd.Series(sdata)查询
根据标签索引查询,类似python的字典
s2['a'] # 查询一个
s2[['a','b']] # 查询多个,返回类型为SeriesDataFrame
每列可以是不同的类型,既有行索引(index)也有列索引(columns),可以被看作由Series组成的字典。
生成
data = {
'da':['dade','dawd'],
'34':['3442','rw2']
}
df = pd.DataFrame(data)查询
df['year'] # 查询一列,返回类型为pd.Series
df[['year','pop']] # 查询多列,返回类型为pd.DataFrame
df.loc[1] # 查询一行
df.loc[1:3] # 查询多行
df.loc[(day, origin), destination] # 双重索引其他
# 设置索引
df.set_index('列名', inplace=True)
# 设置列的数据类型
df["列名"].astype('int32')
df.shape # 返回(行数,列数)数据查询
df.loc # 根据行、列的标签值查询
df.iloc # 根据行、列的数字位置查询
df.where
df.queryloc
- 使用单个label值查询
- 使用值列表批量查询
- 使用数值区间进行范围查询
- 使用条件表达式查询
- 调用函数查询
loc可以查询,也能覆盖写入
df.loc['行','列']
df.loc['',['','']]
df.loc[['', ''], ['', '']]
df.loc[:,"列名"] # 对某列的所有行进行修改
# 使用条件表达式
df.loc[df['列名']<-10, :]
# 调用函数查询
df.loc[函数名, :]字符串处理
Object即字符串
- 先获取Series的str属性,然后在属性上调用函数
- 只能在字符串列上使用,不能再数字列上使用
- DataFrame上没有str属性和处理方法
- Series.str不是Python原生字符串,而是自己的一套方法
df['列名'].strSeries — pandas 2.2.1 documentation (pydata.org)官方文档
排序
Series.sort_values(ascending=True, intplace=False)
# ascending:默认True升序,False降序
# inplace:是否修改原始Series
DataFrame.sort_values(by, ascending=True, intplace=False)
# by:字符串或者List<字符串>,单列排序或多列排序增删改查
增列
- 直接赋值
- df.apply
- df.assign
- 按条件选择分组分别赋值
改
- 使用
at或iat方法根据行和列的标签或索引修改单个值。 - 使用
loc或iloc方法根据行和列的标签或索引修改多个值。 - 使用
replace方法替换特定值。 - 使用
applymap方法对整个DataFrame应用函数。
# 使用at方法修改单个值
df.at[0, 'A'] = 10
# 使用iat方法修改单个值
df.iat[1, 1] = 50
# 使用loc方法修改多个值
df.loc[:, 'A'] = [100, 200, 300]
# 使用iloc方法修改多个值
df.iloc[:, 1] = [400, 500, 600]
# 使用replace方法替换特定值
df.replace(100, 1000)
# 使用applymap方法对整个DataFrame应用函数
def square(x):
return x * x
df.applymap(square)遍历所有值
单索引+DateFrame
for index, row in data1.iterrows(): # 返回行索引和行数据
for col in data1.columns:
print(f"索引: {index}, 行: {row},单个值:{col}")双层索引+Series
for (first, second), value in series.iteritems():
print(f"索引: ({first}, {second}), 值: {value}")数据统计函数
汇总类统计
df.describe() # 一下子提取所有数字列统计结果
df[''].mean() # 查看单个Series的数据
df[''].max()
df[''].min()唯一去重
一般用于枚举、分类列
df[''].unique()按值计数
df['列名'].value_counts() # 返回Series相关系数和协方差
df.cov() # 协方差矩阵
df.corr() # 相关系数矩阵
df[''].corr(df['']) # 计算两者的相关系数缺失值处理
分组
df.groupby['列名'].聚合函数多层索引
pandas的分层索引 (MultiIndex) 讲解_pandas multiindex-CSDN博客
创建
创表时设置index使用列表嵌套
df1 = pd.DataFrame(da,index=[["a","a","b","b","c","c"],
["期末","期中","期末","期中","期末","期中"]],
columns=["语文","英语","数学"])使⽤MultiIndex.from_product()方法构建
names=["a","b","c"]
exems=["期中","期末"]
columns = ["语文","英语","数学"]
index=pd.MultiIndex.from_product([names,exems])
df2 = pd.DataFrame(da,index=index,columns=columns)取值
# 取一组值
df["a"]
# 取一个值
df["a","期中"]